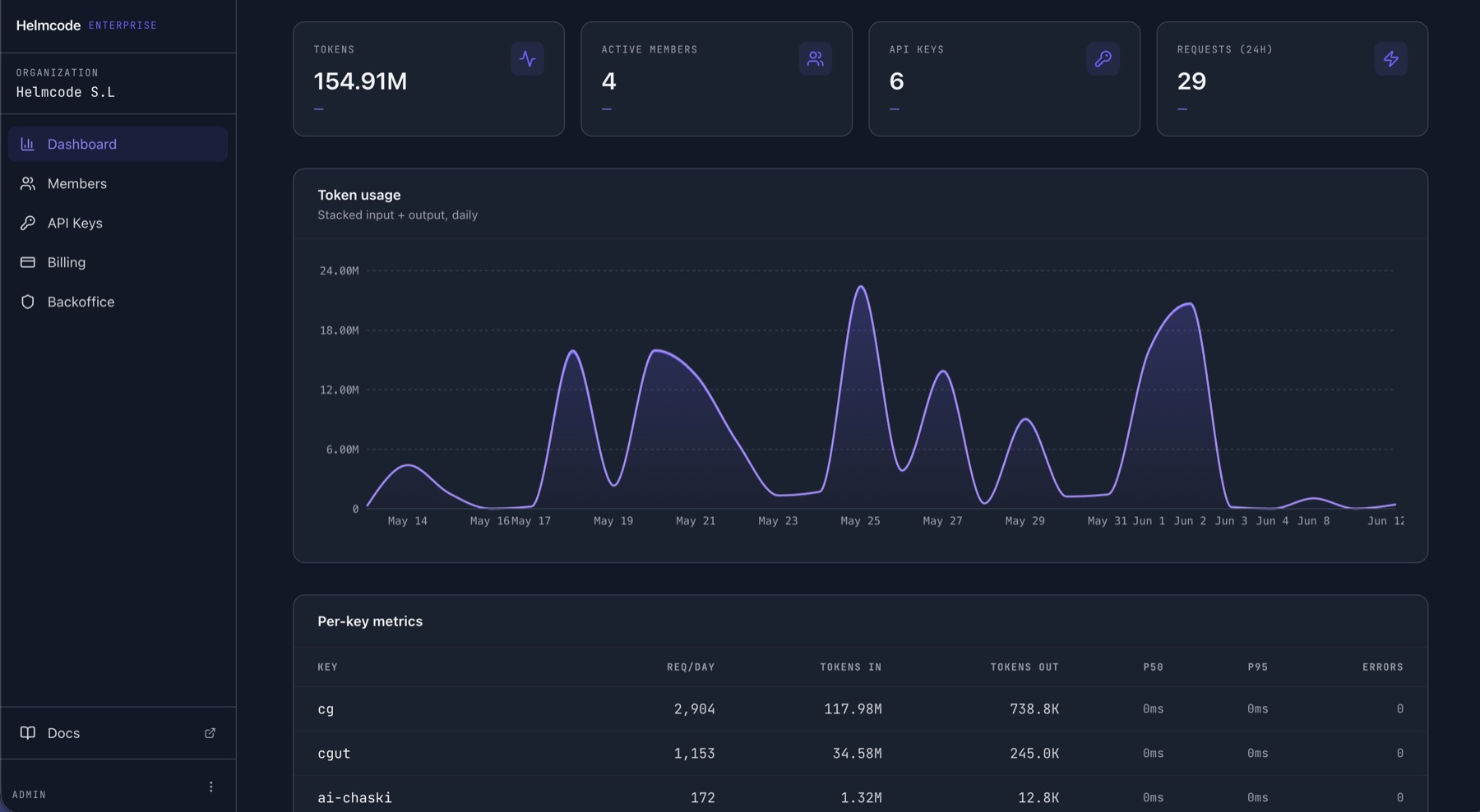
Operation
We run the stack. You ship product.
Private AI infrastructure means GPUs, vLLM, scaling, observability and upgrades. We handle all of it. Forget hiring the AI-infrastructure profiles that barely exist in the market.
// European AI cloud
Run frontier open models through a single OpenAI-compatible API. Zero logs, flat rate, and no infrastructure to manage.








// developer first
Up and running in minutes. Compatible with any OpenAI SDK. Get your API key from the console, change one line, and you're running open models on private European infrastructure.
curl https://api.helmcode.com/v1/models \ -H "Authorization: Bearer sk-your-key-here"
// why helmcode
AI is becoming strategic infrastructure. We operate it for you, so you never have to become an infrastructure company.
Operation
Private AI infrastructure means GPUs, vLLM, scaling, observability and upgrades. We handle all of it. Forget hiring the AI-infrastructure profiles that barely exist in the market.
Cost
Commercial APIs are a great way to start. As usage scales, the bill scales with it. Helmcode turns unpredictable per-token spend into one flat monthly rate, so AI at scale stays on budget and predictable on the P&L.
Sovereignty
Control over your data, your models and your infrastructure. Zero logs, processed exclusively on EU infrastructure, outside the reach of the Cloud Act. We meet GDPR, AI Act and DORA by architecture, not by policy.
// managed inference
Helmcode is managed AI inference. We provision, monitor and operate the full inference stack so your team focuses on product, not on keeping GPUs alive.
// cost comparison
Scenario: 10B tokens/month · 80% input, 20% output · Official prices, June 2026
gpt-5.5 claude-sonnet-4.6 gemini-3.1 qwen3.6 · 35B MoE 80%
Open-model coverage
Open models deliver equivalent results for 80% of enterprise use cases, RAG, classification, code generation, internal assistants. The 20% where you need GPT-5 is more specific than you think.
$250in 9 days
Real-world case
GitHub switched Copilot from flat rate ($19/month per user) to per-token billing. One developer can generate a $250 bill in 9 days. Same workflows. Different pricing model.
// private inference
Unlimited tokens on private EU infrastructure. AI Act ready and GDPR native, so your team ships without waiting for legal, security or DevOps.
No token caps. Rate limits apply per API key — RPM and concurrency — not on total consumption. One key can process 500M tokens in under 24 hours.
Your prompts are never stored. Your code never trains a model. Data processed exclusively in the EU — not on hyperscaler infrastructure subject to the Cloud Act.
Change your base URL and API key. Every OpenAI-compatible client works as-is — Cursor, Zed, OpenCode, Hermes, any SDK. Your existing code runs unchanged.
DeepSeek V4-Flash, Qwen 3.6, Gemma 4. Plus embeddings, reranking, TTS, and STT. The full inference stack — not just text completion.
NVIDIA B200. 192GB VRAM. 256GB DDR5 RAM. We provision, monitor, and upgrade it — you don't touch a single GPU.
99.9% uptime on Scale and above. Continuous monitoring, priority support, and contractual penalties if we miss it.
// models
From long-context reasoning to real-time speech, the full open-model inference stack, production-ready on EU infrastructure.
deepseek-v4-flash sota flagship 284B MoE · 1M context Our flagship for complex, agentic work — long documents, deep codebases and multi-step tool use. Native step-by-step reasoning and tool calling with a 1M-token window.
qwen3.6 35B MoE · 256K context The throughput workhorse. Speculative decoding for 2× speed plus tool calling — ideal for high-volume RAG, classification and code completion.
gemma4 26B MoE · 256K context Google’s open architecture with vision and reasoning. Efficient and capable for everyday assistants and document work.
qwen3-embedding 8B · 4096 dimensions Multilingual semantic embeddings across 100+ languages. MMTEB score 70.58 — the retrieval layer for your RAG pipelines.
rerank 8B · Qwen3 Reranker Cross-lingual semantic reranking. Reorders retrieved passages by true relevance to sharpen RAG results.
kokoro 82M parameters · 67 voices Real-time text-to-speech with sub-second latency. 67 voices, Spanish included — fast enough for live agents and IVR.
whisper-large-v3 99+ languages State-of-the-art speech-to-text. 3.2% WER in Spanish, up to 25MB / ~2 min of audio per request.
Model IDs shown as-is, copy directly into your code.
// enterprise
Same stack. Same API. Same code. The only thing that changes is your level of sovereignty.
Shared
The fastest way to get private inference into production. Managed EU cluster, zero logs and GDPR native — without provisioning a single GPU.
Dedicated
NVIDIA Blackwell hardware reserved for you inside Helmcode's EU infrastructure. Guaranteed throughput, full network isolation and custom models.
On-premise
We deploy and operate the full inference stack inside your datacenter — or a partner facility. Your data never moves. Not a single token leaves your network.
// get started
Skip the AI infra work. Deploy your first private inference endpoint today.
Flat rate. EU data. OpenAI API compatible.
// faq
What engineering and legal teams ask before moving inference in-house.
Change the base URL and API key, that's it. Any OpenAI-compatible SDK or tool works unchanged: Cursor, Zed, OpenCode, your own clients. Most teams are running in production the same day.
Exclusively on EU infrastructure, never on US hyperscalers subject to the Cloud Act. Zero logs: prompts are never stored. GDPR and AI Act compliant by architecture, not by configuration.
No caps on total consumption. Rate limits apply per API key, requests per minute and concurrency, not on how many tokens you process. A single key can handle hundreds of millions of tokens a month.
DeepSeek V4-Flash, Qwen 3.6 and Gemma 4, plus embeddings, reranking, TTS and STT. On Dedicated and On-premise you can also run custom or fine-tuned models.
A flat monthly rate per API key, not per token. From €399/month, no usage surprises and no long-term commitment. Your CFO gets a fixed line on the P&L.
99.9% uptime on Scale and above, with continuous monitoring and priority support. For strict compliance, we deploy and operate the full inference stack inside your own datacenter, not a single token leaves your network.
// cookies
We use strictly necessary cookies to run the site and, only with your consent, Google Analytics to understand usage. No advertising, ever — see our Cookie Policy.
// preferences